

二分类器与多分类器的差异主要体现在处理问题的类型损失函数的设定以及参数的构成上二分类器是针对二项分布的模型构建分类器区别,而多分类器则处理多项式分布的情况二项分布是多项式分布的一种特殊情况分类器区别,二者同属分类问题范畴在损失函数上分类器区别,二分类问题通常选用sigmoid损失,而多分类问题则适用softmax损失分类器区别;在分类过程中,需要使用已经标记好的训练数据集来训练分类器,这些数据集包含特征向量和相应的类别标签分类器的构建可以通过统计方法机器学习算法或神经网络等多种技术实现聚类则是一种无监督学习方法,它不需要预先定义的类别聚类算法的目的是将数据集中的对象自动划分为不同的群组,这些群组内部的。
1 分类和聚类的区别在于,分类是在事先定义好的类别中进行划分,类别数不变分类器需要通过人工标注的分类训练语料进行训练,属于有指导学习范畴而聚类则没有事先预定的类别,类别数不确定在聚类过程中,类别是自动生成的2 分类适合在类别或分级体系已经确定的情况下使用,比如按照国图分类法对;朴素贝叶斯分类器Naive Bayes Classifier,简称NBC是一种基于概率的分类方法,其理论基础坚实,分类效率稳定NBC模型所需估计的参数较少,对缺失数据的敏感度较低,且算法相对简单理论上,NBC模型在分类准确率上具有优势,但实际应用中,NBC模型假设各个特征彼此独立,这在很多情况下是不成立的例如;分类是数据挖掘中的一项非常重要的任务,利用分类技术可以从数据集中提取描述数据类的一个函数或模型也常称为分类器,并把数据集中的每个对象归结到某个已知的对象类中从机器学习的观点,分类技术是一种有指导的学习,即每个训练样本的数据对象已经有类标识,通过学习可以形成表达数据对象与类标识间。
二分类多分类与多标签的基本概念 二分类表示分类任务中有两个类别,比如我们想识别一幅图片是不是猫也就是说,训练一个分类器,输入一幅图片,用特征向量x表示,输出是不是猫,用y=0或1表示二类分类是假设每个样本都被设置了一个且仅有一个标签 0 或者 1多类分类Multiclass;我觉得大体是一样的DNN深度神经网络这个概念其实比较宽泛吧,比较深的网络都好这么称呼吧,就是一些卷积神经网络和循环神经网络但是一般说DNN的时候指的就是多层普通的神经网络别的具体的可能会特别说明,也就是MLP多层感知机有区别的情况,就是DNN是一个更大的概念;3 分类与聚类的主要区别在于,分类预先设定类别,且类别数量固定分类器通常通过人工标注的训练数据集训练得到,属于有监督学习4 聚类则不预设类别,类别数量可变聚类无需人工标注和预训练分类器,类别在聚类过程中自动生成5 分类适用于类别已确定的场景,如图书按照国图分类法分类聚类适用于类;只要是基於贝叶斯理论的分类器就可以叫贝叶斯分类器,朴素贝叶斯分类器的叫法是因为它是优化过的一种运算性能高的算法wikipedia 上的英语页只给了朴素贝叶斯分类其的定义贝叶斯网络是一种基於贝叶斯理论以 DAG 形式描述全局概率分布的一种统计方法,不属於分类器的一种,主要用於贝叶斯推断;聚类和分类的主要区别如下先验知识分类在分类任务中,通常已经知道了类别的标签,即事先知道有哪些类别以及各类的典型特征分类是用已知类别标签的样本集去训练一个分类器,然后用该分类器对其分类器区别他未知类别的样本进行分类聚类聚类则是在事先不知道欲划分类别的情况下进行的它是一种无指导学习;分类回归聚类的区别 分类和聚类是两种不同的数据分析方法它们的主要区别在于,分类需要预先定义好类别,而聚类不需要分类器需要由人工标注的分类训练语料训练得到,而聚类则是在聚类过程中自动生成类别分类适用于类别已经确定的场合,如按国图分类法分类图书而聚类适用于类别不确定的场合,如多文档文摘。

深度学习领域中,DNN分类器与MLP分类器在结构与应用上有显著区别MLP分类器,即多层感知机,其核心特征为包含输入层输出层与至少一个隐层,结构简单,原理与感知机相似,但更适用于复杂问题的解决而DNN分类器,即深度神经网络,继承自MLP,但更加强调深度结构,隐层数量增加,同时集成了学习率优化;在分类问题中,因变量Y可以看做是数据的label,属于分类变量所谓分类问题,就是能够在数据的自变量X空间内找到一些decision boundaries,把label不同的数据分开,如果某种方法所找出的这些decision boundaries在自变量X空间内是线性的,这时就说这种方法是一种线性分类器贝叶斯分类器的分类原理是通过某对象的;综上所述,线性分类器与非线性分类器在处理数据集的能力上有明显的区别线性分类器适用于简单线性可分的数据集,而非线性分类器则能处理更复杂线性不可分的数据集通过特征提取等技术,我们甚至可以利用线性分类器对非线性数据进行分类。
贝叶斯分类器的分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类也就是说,贝叶斯分类器是最小错误率意义上的优化目前研究较多的贝叶斯分类器主要有四种,分别是Naive BayesTANBAN和GBN贝叶斯网络是;区别是,分类是事先定义好类别 ,类别数不变 分类器需要由人工标注的分类训练语料训练得到,属于有指导学习范畴聚类则没有事先预定的类别,类别数不确定 聚类不需要人工标注和预先训练分类器,类别在聚类过程中自动生成 分类适合类别或分类体系已经确定的场合,比如按照国图分类法分类图书聚类则;相对地,聚类则是在无监督学习中应用较多,它通过分析数据之间的相似性,自动形成类别,无需事先设定标签例如,根据消费者的购买习惯,将他们自然地分到不同的群体中,以便进行更有效的市场分析分类的一个关键特点是它依赖于已知的标签来指导模型的训练,这意味着分类器可以通过学习标注好的数据来提高。

























































































































































































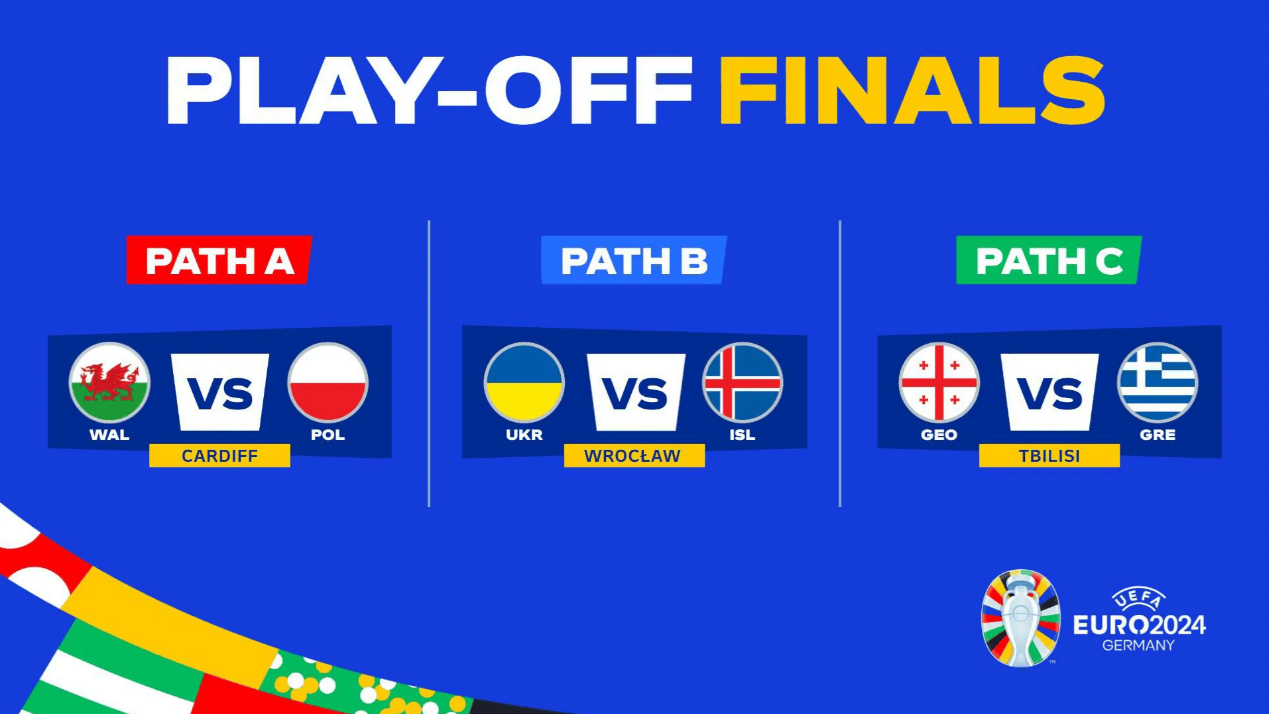

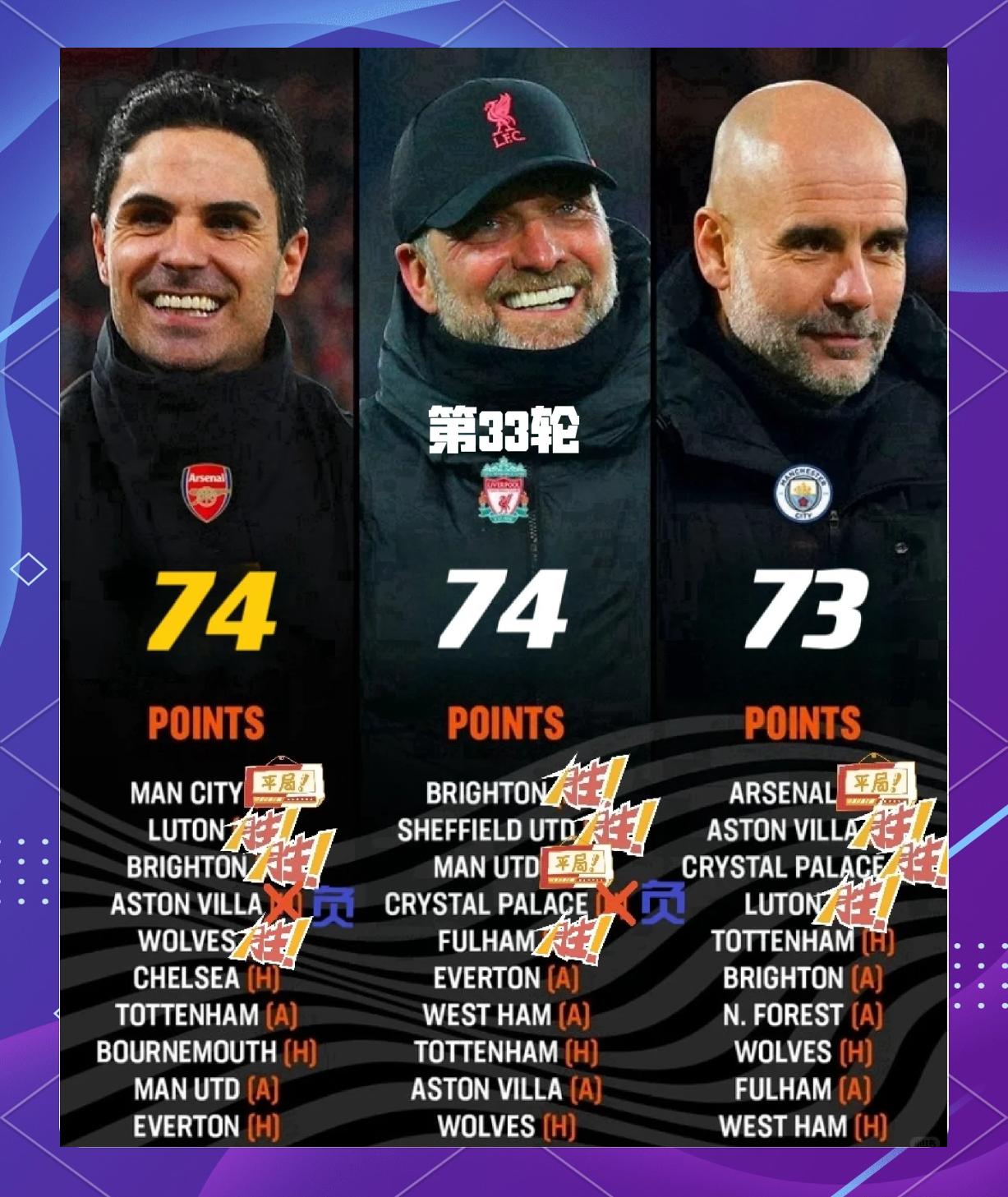





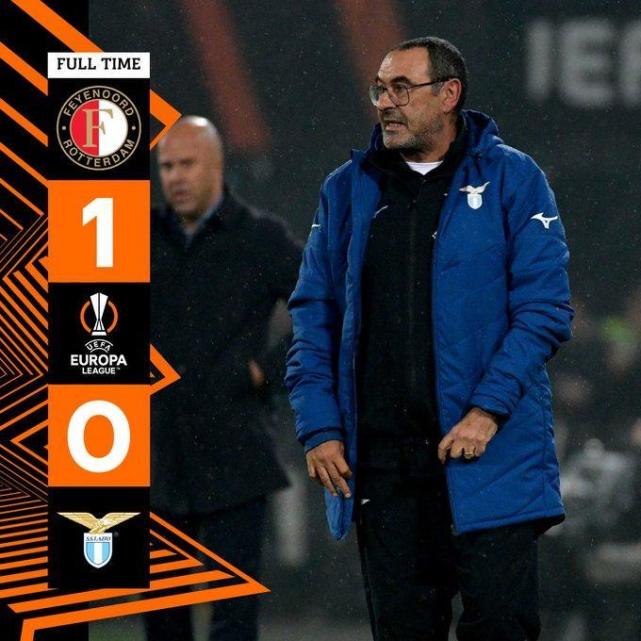




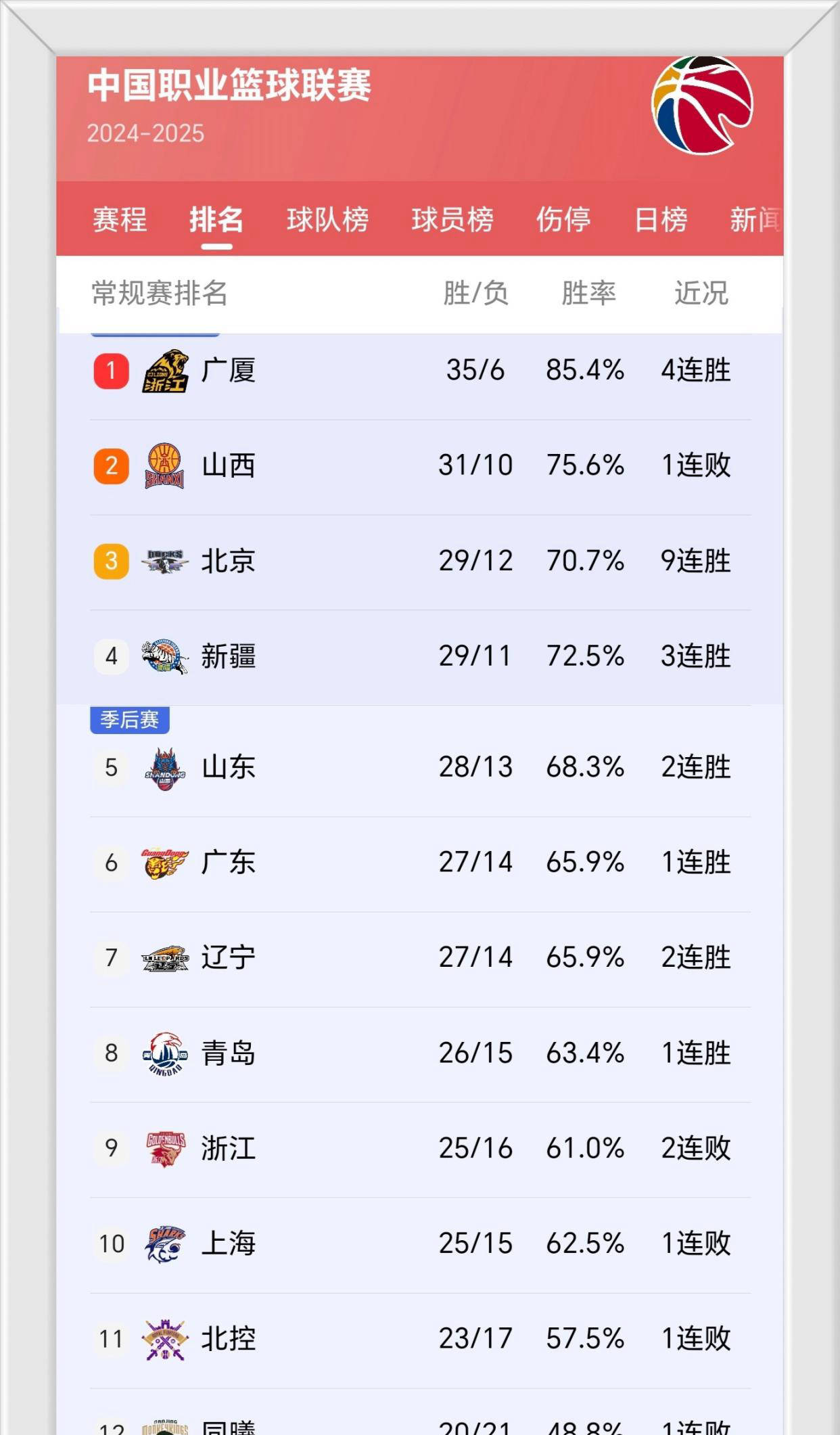











































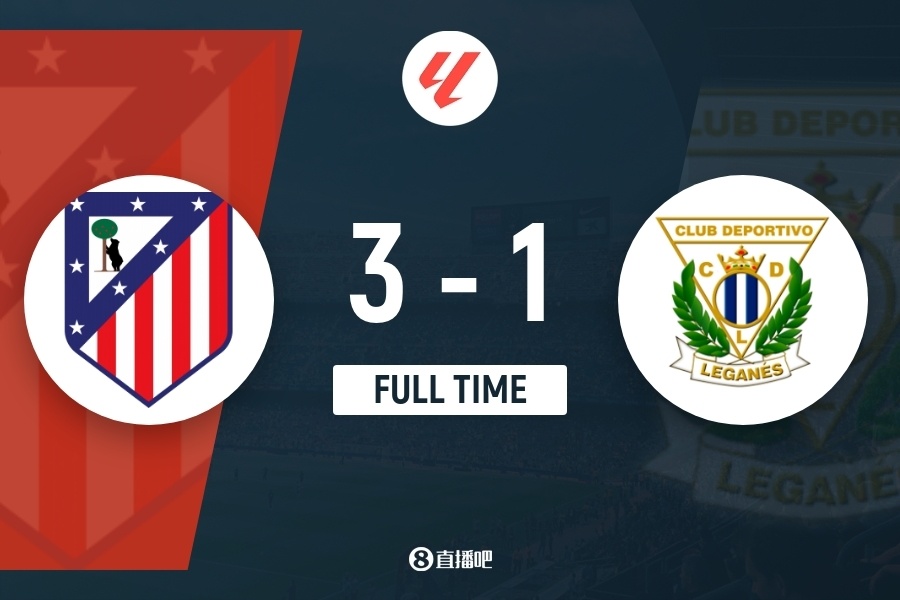


























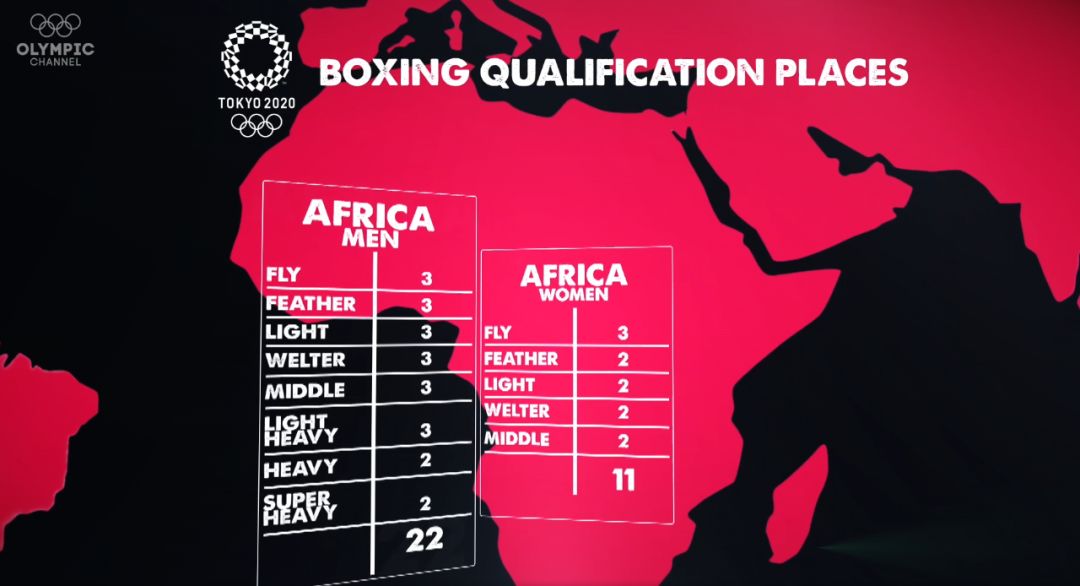

















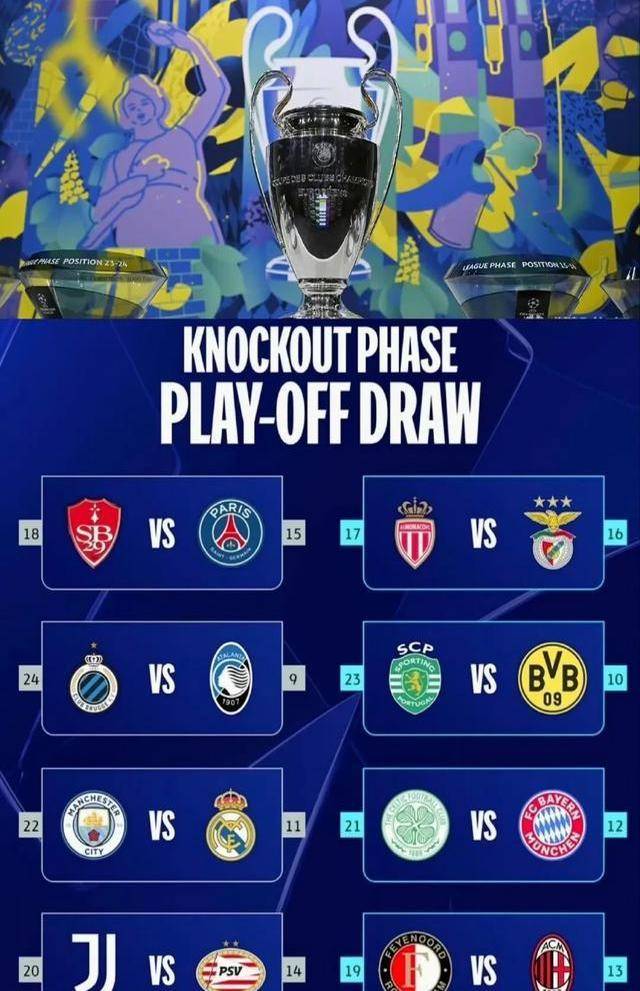
























































































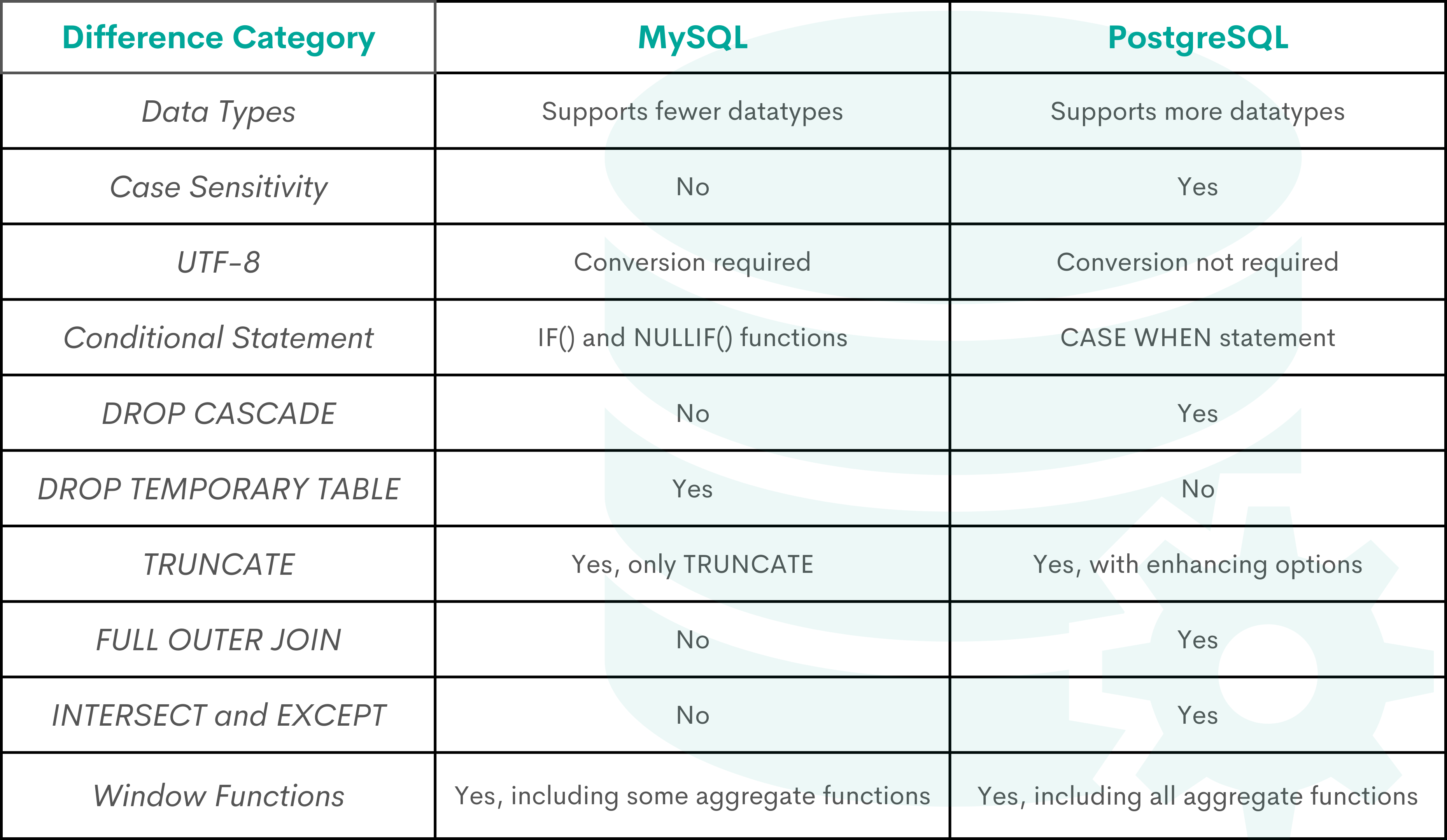


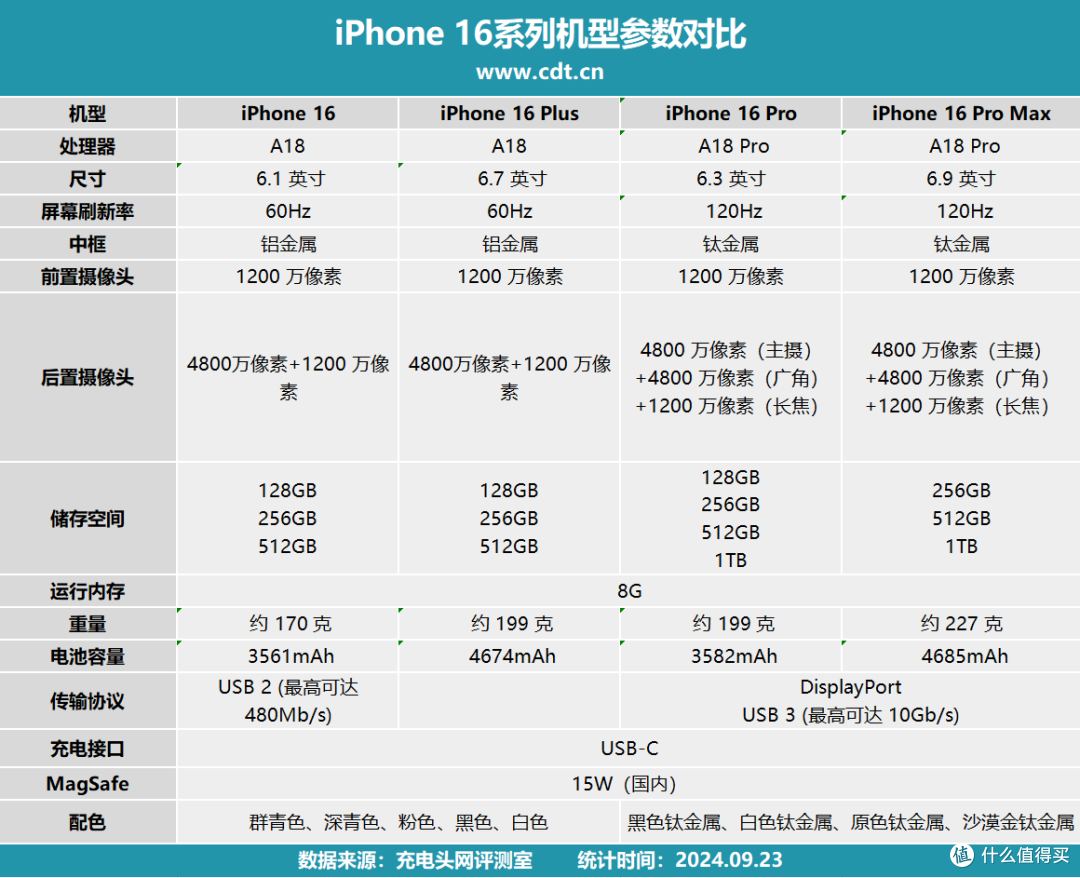



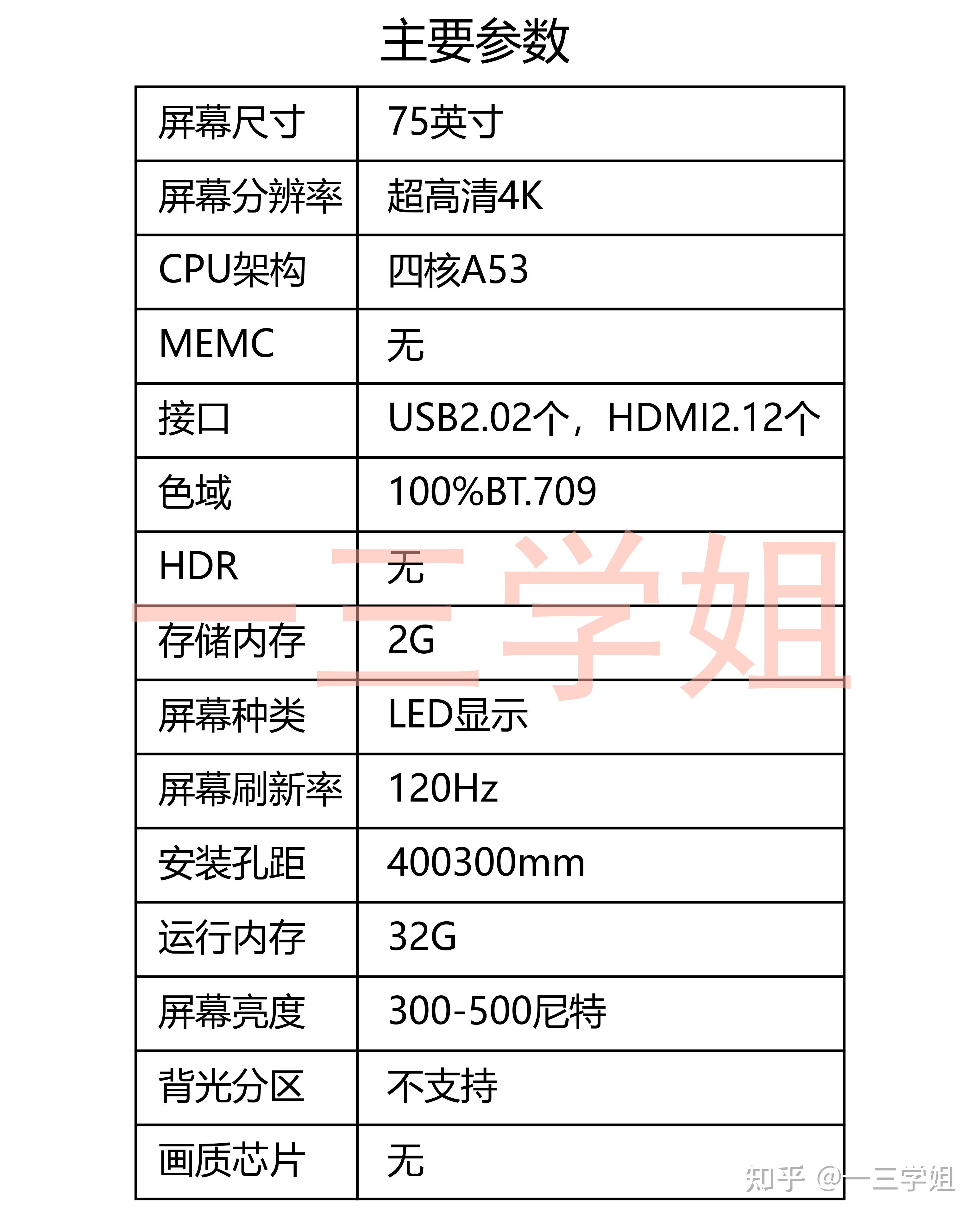






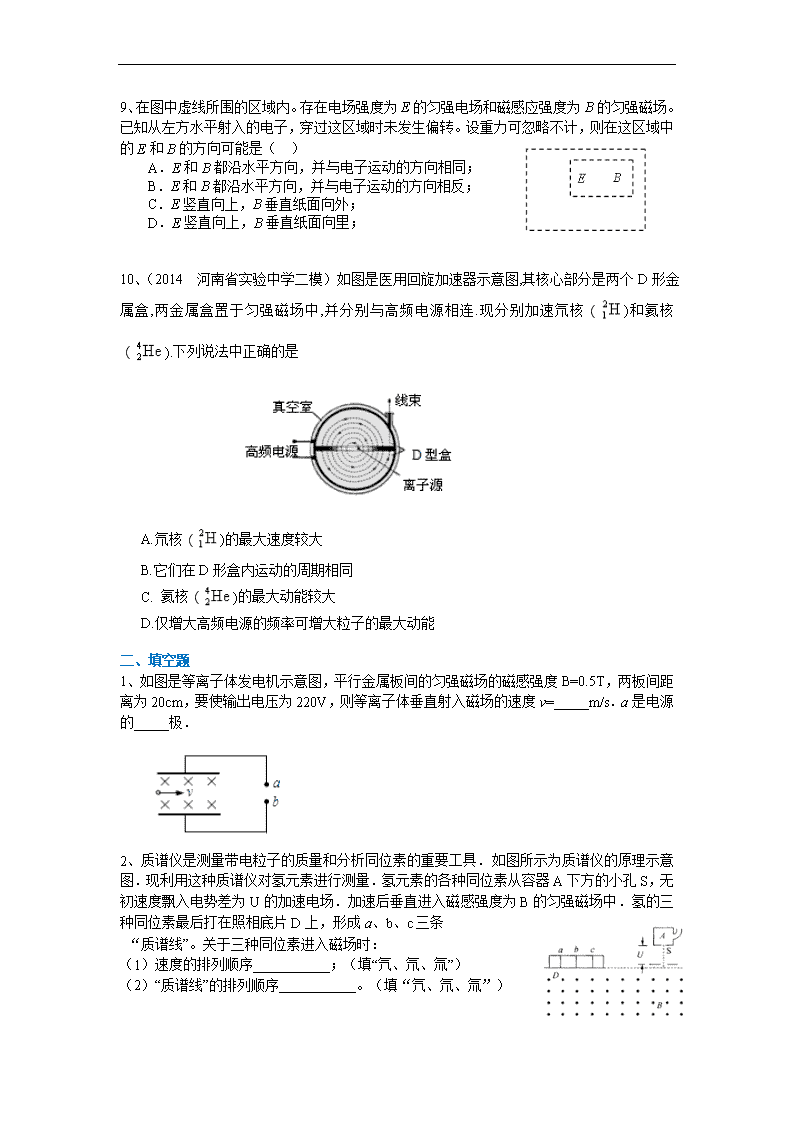









































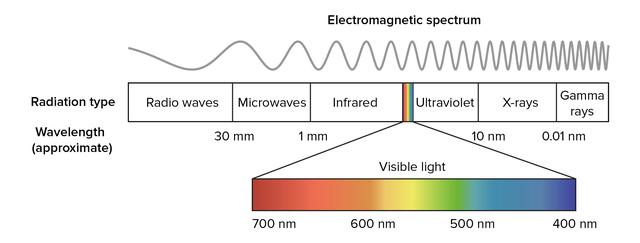
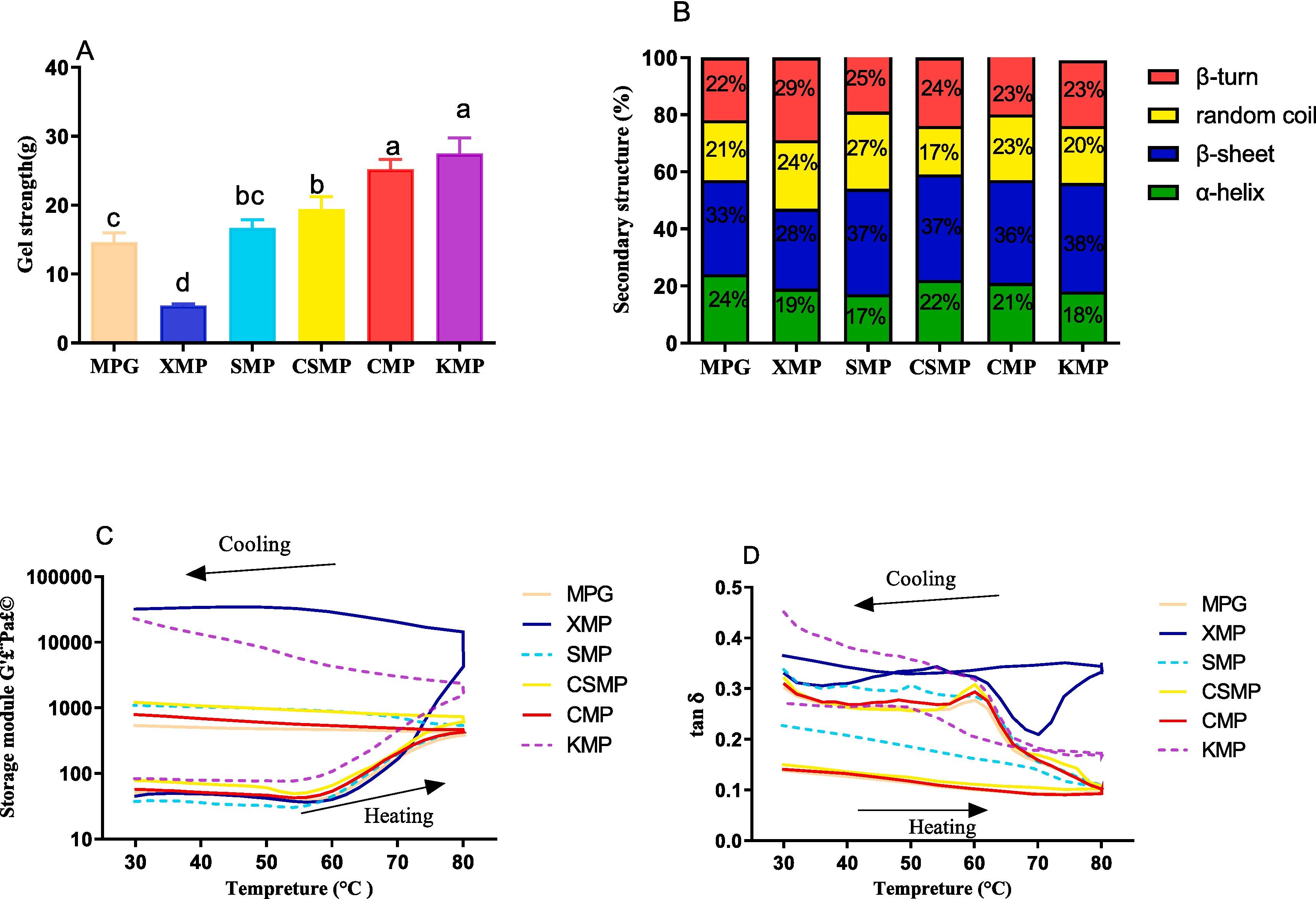







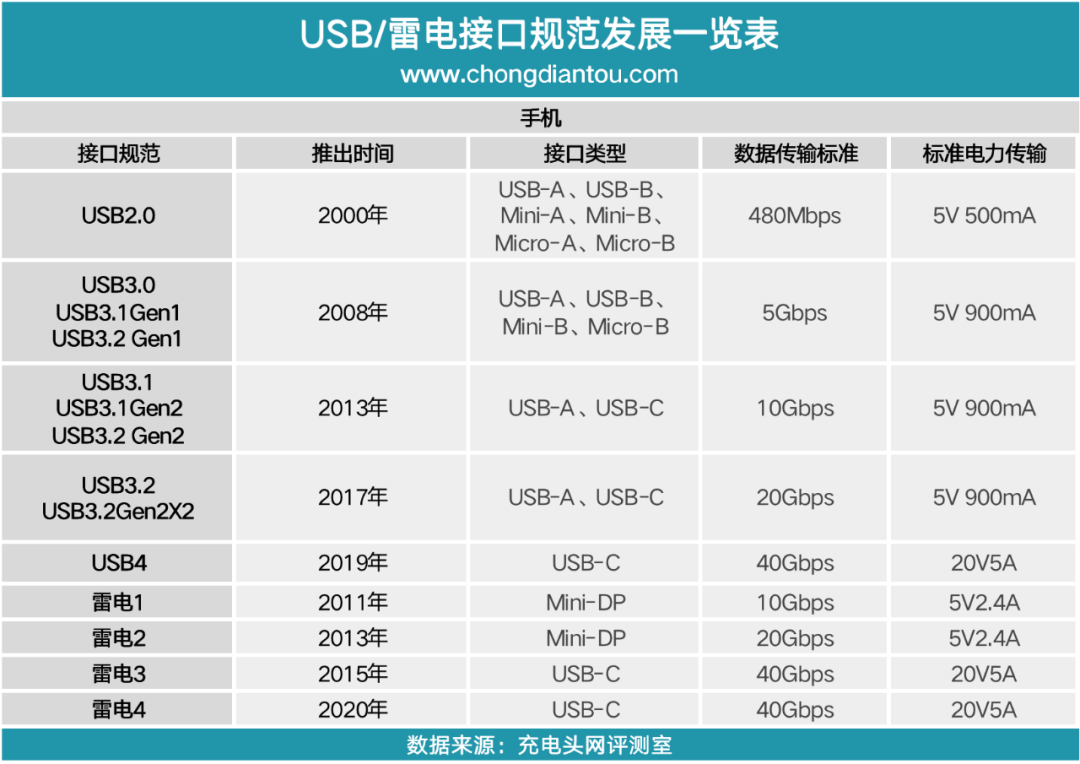

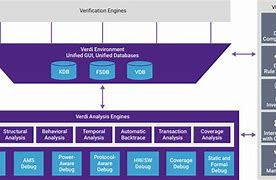











































































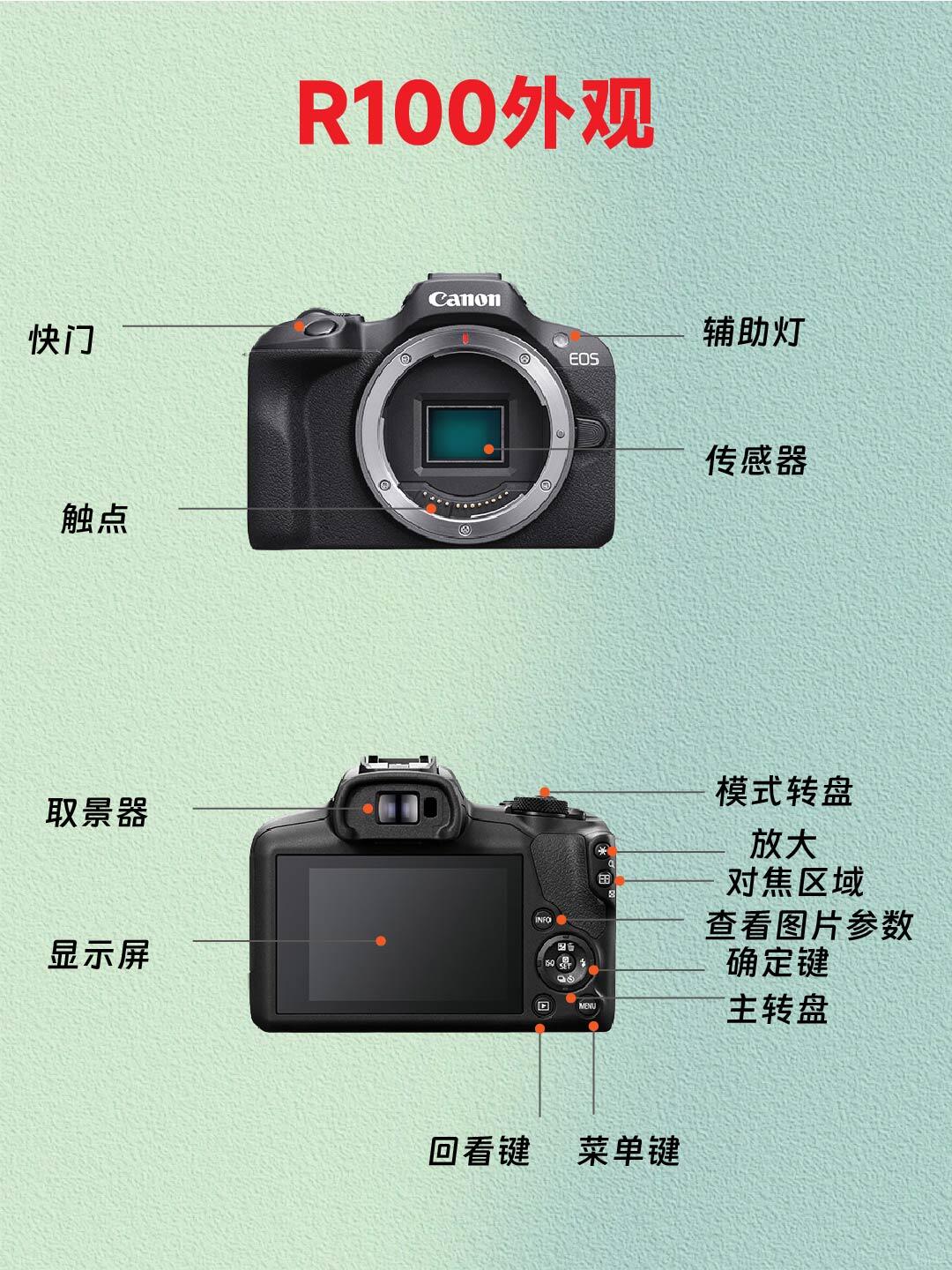


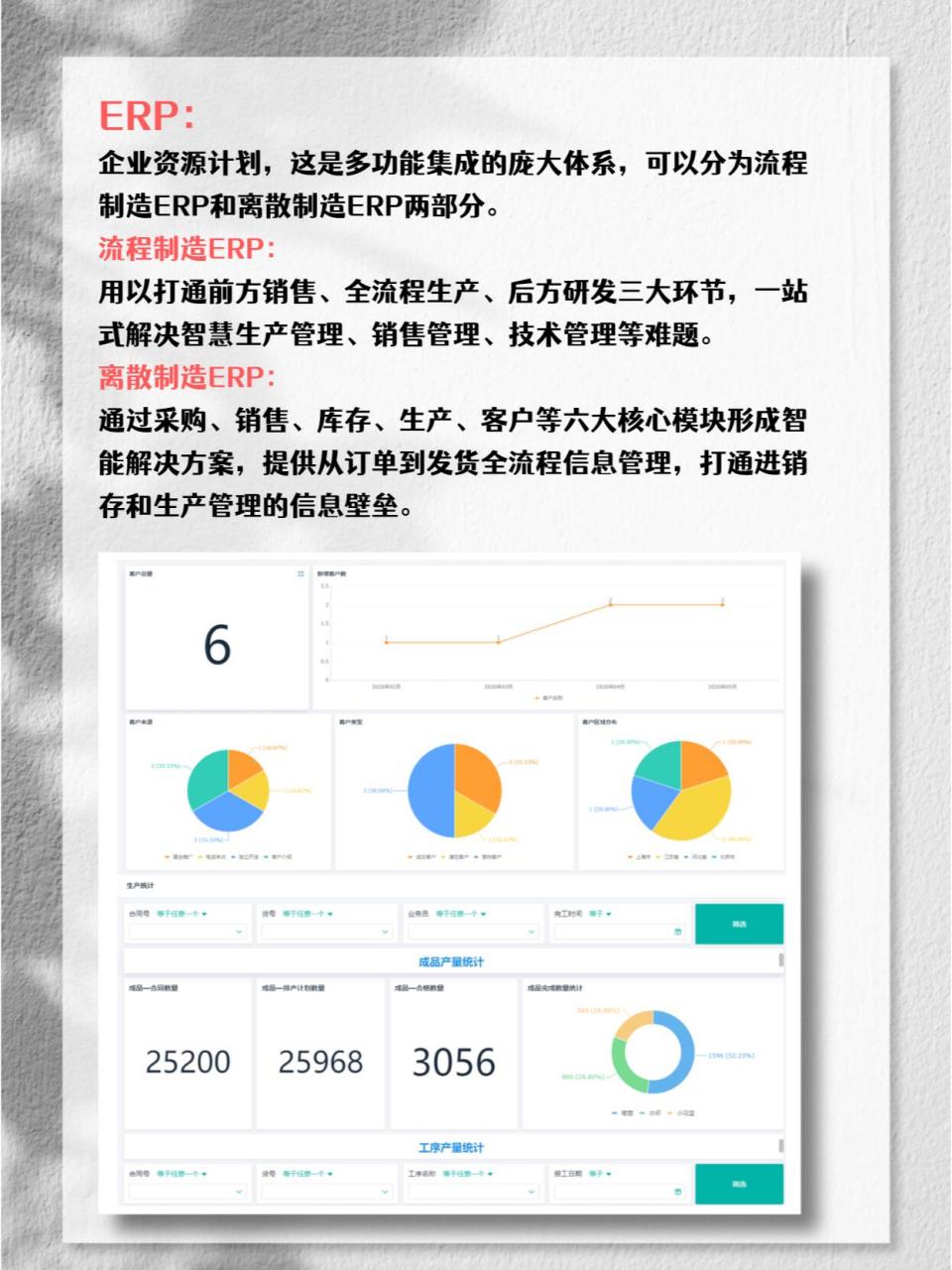





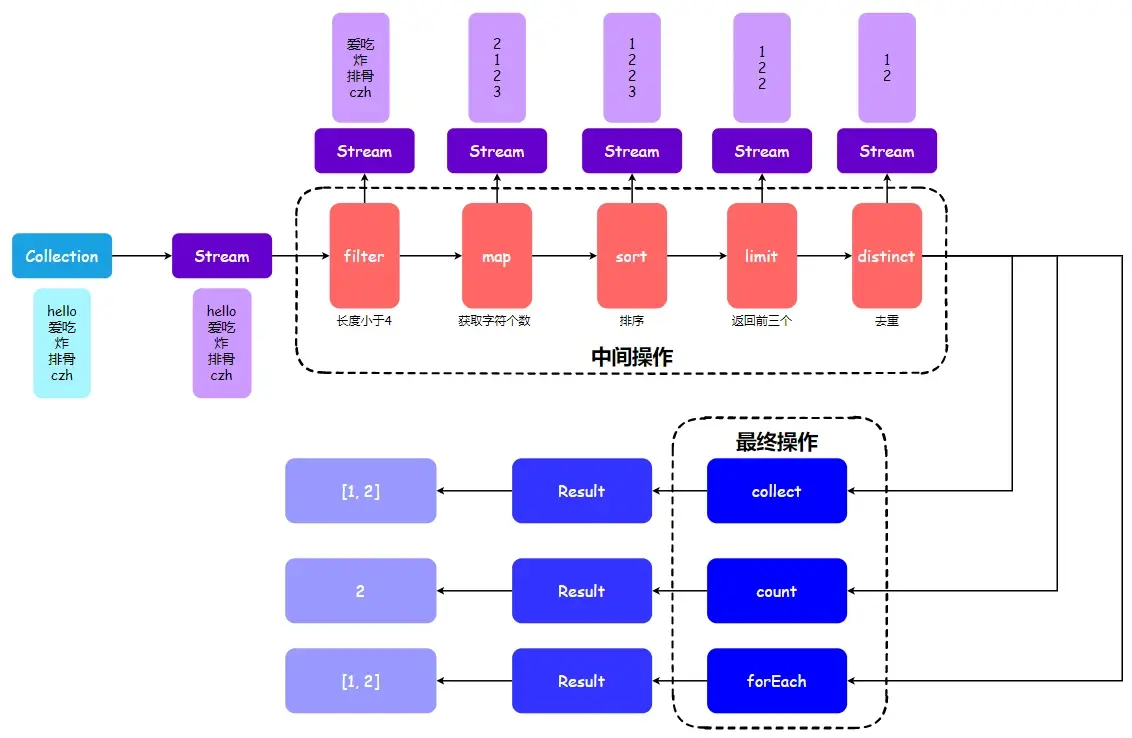

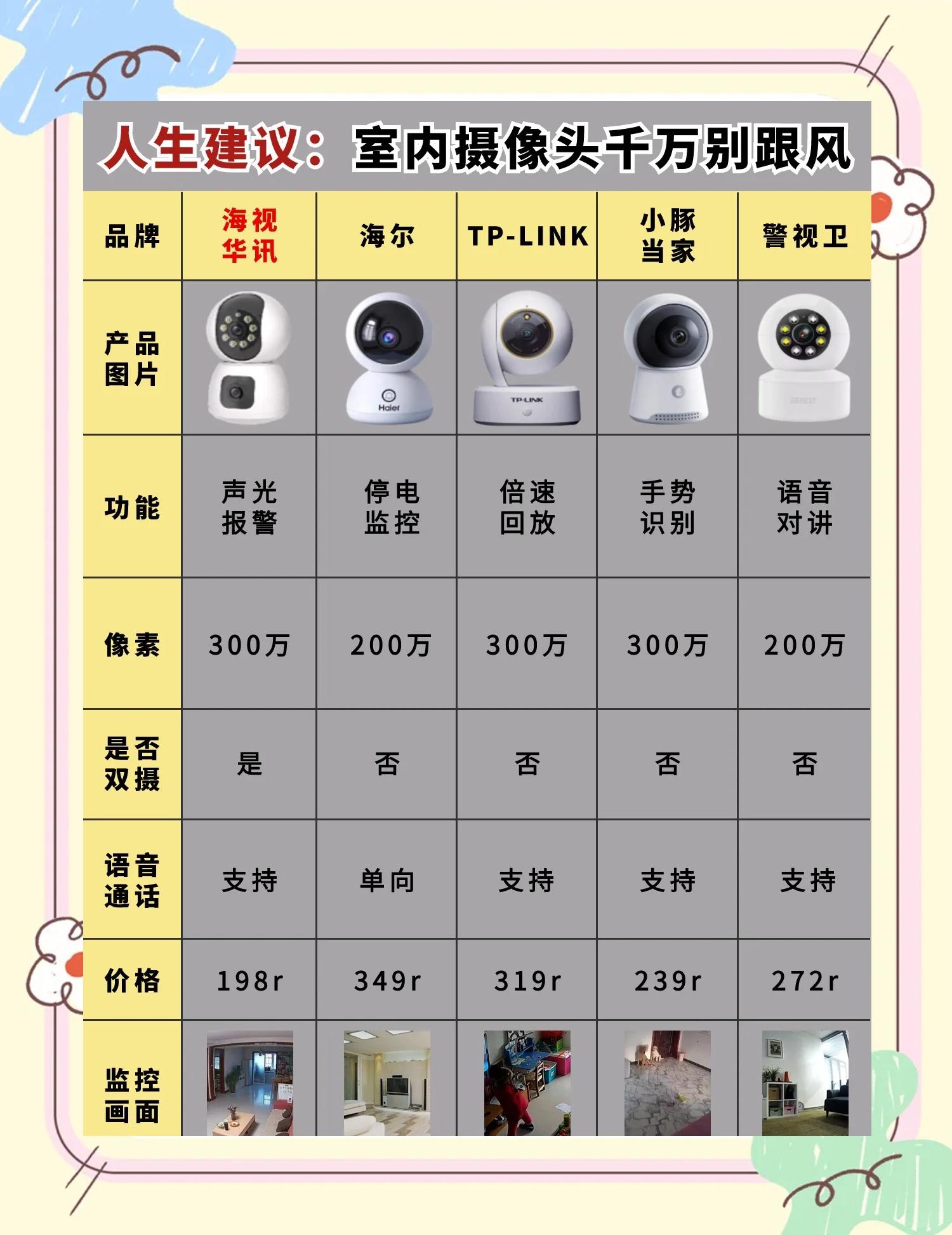

































网友评论
最新评论